Better docs, less pain: the case for new docs-as-code standards
Despite the massive growth of docs-as-code as a documentation ethos, I continue to be surprised, year after year, by the lack of robust docs-as-code tools. Most days it feels as if docs-as-code was a giant standing on feet of clay, on the fragile toolchains that we use to create our documentation in all kinds of software companies, from startups to unicorns.
The fragility of docs-as-code tooling means that software companies must content themselves with Rube Goldberg machines that require extensive care and maintenance. Teams fight a daily battle to keep a ragtag bunch of open source utilities working together, dodging bugs and inventing mods that rarely feed back to the community. (Though all of that is probably true for most software development nowadays.)
I’m a doctool person, too: I spend an inordinate amount of time testing, using, and hacking tools for documentation. It’s both fun and frustrating. And while I acknowledge that tools by themselves are useless if one doesn’t take people and workflows into account, I’m also aware that bad tools can hinder growth and speed and collaboration.
Don’t we all want better tools? We do. But to have better tools, I believe we must address first some systemic issues affecting how docs-as-code is done these days, that is:
- The lack of a standard, lightweight markup language for docs
- The lack of universal documentation rendering in all devices
- The lack of distributed version control systems designed for docs
Only then we’d be able to create tools that really work, or that at least work better than what we’re using right now. We shouldn’t really be caring that much about tools, or spend that much time discussing them. We should rather be writing.
We need a standard, lightweight markup language for docs
You know Markdown? It’s a lightweight markup language, and the most popular at that, owing also to its adoption as the new README file standard in git repositories. If we’re talking about docs-as-code these days, we must thank Markdown for that.
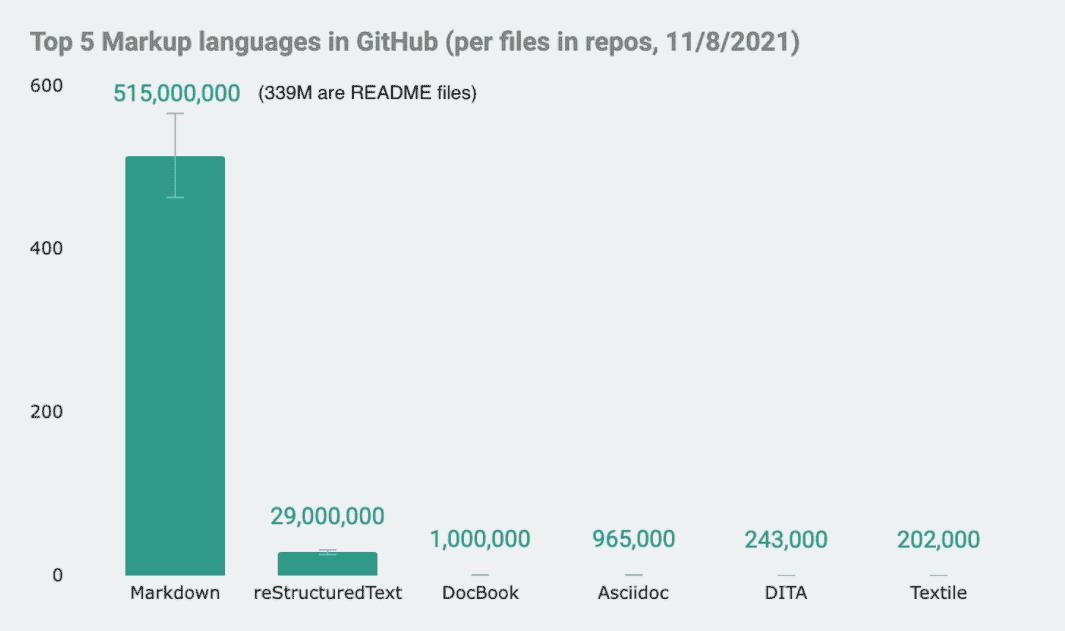
Most lightweight markup languages, such as Markdown and Asciidoc, were invented to solve a deceivingly simple problem: How can writers add semantic and formatting metadata to documents in a text editor while preserving readability and ease of use? While feature-complete and well equipped for semantics, their predecessors, DITA and DocBook, aren’t very friendly to text editors, which is the main tool of software engineers.
Consider this DITA snippet:
<task id="install_emacs">
<title>Installing GNU Emacs</title>
<taskbody>
<prereq>Windows NT 4.0 or any subsequent version of Windows. 5Mb of free
disk space.</prereq>
<steps>
<step>
<cmd>Unzip the distribution anywhere.</cmd>
<info>We recommend to use the free, open source, <xref format="html"
href="http://www.info-zip.org/" scope="external">Info-ZIP</xref>
utility to do so.</info>
</step>
</steps>
</taskbody>
</task>
More than half of the characters in the snippet above are pure XML; the rest is the actual content. That makes sense if you consider how much information one may need to embed in documents to achieve correct rendering in multiple channels, like PDFs. But, in most cases, startups and open source projects don’t need that. It’s overkill. Plus, nobody really likes editing the source of XML documents: it’s heavy on the eyes, hard to parse by human beings, and hard to edit. Developer experience matters, and software developers frequently own the documentation of their projects, especially in open source settings, where they need a simple markup language to get their README files up and running.
To understand this better, picture a universal tool, DITA, that can do all you need, but weighs 300 kg. You know how to use it, but the developers you work with are used to 300 gr notepads. Would you give DITA to them? Would it help collaboration? No. You’d end up using the 300 gr notepad (Markdown) because it’s simpler, faster, and fosters collaboration, which is key in the Agile era. The core tenet of docs-as-code is getting everyone to work together, and we should credit Markdown for enabling that.
The problem with Markdown is that it wasn’t invented with documentation in mind. While it can help you get the job done for simple documents, Markdown painfully shows its limitations when it comes to things like content reuse, internal references, or even tables. Inspired by the syntax of plain text emails, John Gruber and Aaron Swartz aimed at creating a simple convention limited to elemental formatting.
Markdown is a text-to-HTML conversion tool for web writers. Markdown allows you to write using an easy-to-read, easy-to-write plain text format, then convert it to structurally valid XHTML (or HTML). […] The overriding design goal for Markdown’s formatting syntax is to make it as readable as possible. The idea is that a Markdown-formatted document should be publishable as-is, as plain text, without looking like it’s been marked up with tags or formatting instructions.
A number of markdown languages appeared to bridge the gap between the ease of use of Markdown and the feature-completeness of the XML-based standards of yore: The two most notable alternatives are Asciidoc and reStructuredText, though they also fall short of providing a solution. This Tower of Babel state of affairs where we’ve dozens of markup languages cohabiting in the same space has led tool makers to support several languages at the same time; it’s not uncommon to find a mix of rST, Asciidoc, and Markdown in the same git repository, with some glorified pandoc piping acting as duct tape.
Much like it happened with OpenAPI for REST API specifications, I’d love to see a consortium of big, medium, and small companies working together to draft a new open standard for software technical documentation. We’d call whatever suits our taste—OpenREADME, OpenRTFM, CommonDocs—it wouldn’t really matter as long as it’d have:
- Ease of use comparable to Markdown: Plain text without the XML fat
- That means producing documents you can still read
- It also means writing docs without the feeling of using LaTeX
- One should be able to pick up the basics in an hour or less
- Same feature set of best-in-class languages, such as DITA and DocBook
- Content reuse, references, glossaries, and so on
- Some features still missing? They shall be added
- Completely open source: No proprietary interest or vendor lock-in
- Open source tooling (linters, validators, renderers, etc.)
- Anyone can contribute to the standard (not just big companies)
It doesn’t have to be new. It could be one of the major markup languages (or one of the existing Markdown extensions, such as MyST), only expanded and distributed with enough publicity and resources to evolve to something better, to an ecosystem of applications that doesn’t merely evoke a feeling of “oh, all right, one more language to learn”. Imagine an open-source, FAANG-backed markup language for docs: If such a language existed, the docs-as-code community would not only rejoice, but also gain business credibility.
Why such a standard still doesn’t exist can only be guessed. One reason could be that engineers are happy enough with Markdown to bother. That’s why technical writers should co-own the creation of a standard like this: If left exclusively to engineers, we may end up with yet another version of the same stuff we’re using today, plagued by constructs and patterns that resemble programming languages more than structured prose. There must be more “docs” than “code” in docs-as-code, and I firmly believe that falling into the “code” pattern can be avoided by involving writers more.
I’ve been reminded that Lightweight DITA exists (and so does MDITA). It might be the solution to the above issues, if repackaged in an attractive, DevRel friendly way.
We need universal docs rendering on any device
Documentation should render in any viewer application by just parsing source files, without the need of invoking any third party component or library, not unlike the experience of loading a MOBI file in your Kindle. That is what HTML aimed at accomplishing back when it was invented, though HTML didn’t make any assumption about the structure of documents other than they had headings and paragraphs and tables. HTML5 isn’t much more opinionated, because it’s not its job—and that’s fine.
If a standard markup language like the one I’ve described above sees the light, the natural step for browsers and SDKs for native applications would be to create a new standard for rendering and styling technical documentation, so that you could load a document.rtfm file on any device and have a similar docs experience everywhere. If that thought brings back memories of things like WinHelp, man pages, or the standardized UI widgets of Motif, you are on the right track: It’s about enabling a (as-much-as-possible) fail-safe, basic way of consuming docs everywhere.
I don’t think technical writers deeply care about their docs having a unique look and feel in the first place. Rather, we want documentation to render in a predictable way, with all the elements we need (tables, menus, expansion blocks, tabs, accordions, and so on), without the need of tinkering with custom layouts or style sheets. The primary goal for a doc is to be read whenever is needed by the largest number of interested users, without encumbering the client with tons of JavaScript garbage.
Having a standard for how documentation is rendered doesn’t mean that you wouldn’t be able to customize the look and feel. The docs source could be processed in any number of ways to add features on top of the basic rendering, or to override styling. You want to embed the docs in the product UI? That’s fine, but that development should not prevent the original doc from loading in a universal, accessible, and predictable way if the user wants that. To summarize, I’d like to see a “Read mode” for docs, anywhere.
We need a better version control system for docs
Git has become the most popular version-control system, and with the advent of docs-as-code, it was all too natural to follow the same paved way that lay in front of developers. So we use git and GitHub and GitLab. But are they the most appropriate system for versioning documentation in a collaborative environment? We’re sort of assuming that git is the version control system for docs-as-code. It just happens to be the most popular. What if Mercurial or GNU Bazaar won the VCS wars fifteen years ago?
Now, part of what makes docs-as-code popular is that writers and developers can work together in the same repos. Git’s stability and de-facto status as an industry standard make for less headaches. But git is far from perfect: Writers need to fit their workflows into the limitations of git, compressing information into commit messages and relying on other systems for reviews and context. Git is also notoriously inadequate for versioning media files. And it’s so difficult to master that countless git UIs have been created.
Solutions ranged from adopting add-ons that bring review workflows and comments to version-control systems (like Collaborator) to resorting to a dual system in which writers start with a Google Drive draft and then do the jump to docs-as-code once the review is done. Using git as an engine for a collaboration frontend is serving many teams well, though having to jump back to the terminal to type obscure git commands is still a must.
Designing an alternative system on top of git requires that technical writers start thinking about what they’d like to see in a VCS. For example:
- Greater ease of use—so that sites like ohshitgit.com aren’t needed
- Ability to review content with comments, suggestions, approvals, etc.
- Better handling of media file versioning for diagrams and screenshots
- Support for centralized workflows, or gateway-based flows
Apart from the obvious opportunities for startups to create a layer on top of git that does all that, there might be a space for VCS systems that can play nicely with git and similar tools. Advocates of content management systems (CMS) will say that we have CMS and CCMS for that, but abstracting complexity away in a database is the opposite of docs-as-code; if we want to foster cross-functional collaboration when documenting software, docs must be like code.
What could be different is how the mesh of docs and code could be treated by version control systems. When git was created, docs in repos were a README and comments in the code (it’s still like that for the Linux kernel). The current situation for most projects is different, and docs are regularly spotted alongside code. That corpus of prose, though, is versioned exactly like the code it documents. But does that mean we’re stuck with git, as we’re with Markdown? Interesting projects such as Fossil come to mind (a VCS that includes wikis and technotes in the same binary), but as it happens with Markdown, it’s best to play nicely with all the tech we’re using today than to reinvent the wheel.
Where do we go from here?
To produce software documentation faster, to write less while documenting more, and to scale up docs-as-code solutions without dedicating writers to the task of keeping pipelines operational, we need better tools. Those tools, though, won’t happen if the technical writing community can’t wrap their head around better open standards for things like a unified semantic markup, better version control, and universal docs rendering.
This post aims at opening up that discussion. The next step is working together on new specs for all the above. Will you join that quest? Here are some ideas:
- Join an existing open source project to improve a markup language.
- Try out new technologies for docs rendering and version control.
- Publish your findings.