Docs-as-code topologies
Should docs stay with the code they document? Or should they rather be in a separate repo, fully managed by tech writers and docs site developers? The matter of where docs should be living when doing docs-as-code isn’t easy to untangle. With the following topologies I’ve tried to describe situations I’ve found myself into or seen in the wild. Each has its own pros and cons, though only the last is my favorite.
Sidecar: docs and code living together

In the sidecar pattern, docs are typically stored with the code as Markdown files or as code comments for docs generators, like Javadoc or Python’s docstrings. The most sophisticated among these repos build static docs sites in GitHub pages or external hosting solutions using tools close to their code ecosystem; for example, Sphinx and Doxygen are very popular among Pythonists and C++ users.
Most docs-as-code projects are born as sidecars out of practical reasons: Former experimental projects that begin with docs written by engineers and then graduate to commercial or open-source solutions that require dedicated writers. The docs, though, are still in the repo and remain there for a long time. This is also the most popular approach for internal developer docs, which seldom require a dedicated site.
A sidecar of docs and code is a natural choice when a tech company is still developing an editorial culture, or when most of the docs are reference generated from the code. Docs are updated and versioned with the code, which is advantageous in situations where updates are frequent and important. It’s an excellent starting point for docs-as-code projects in that engineers tend to the docs and writers get a better sense of dev activities. Writers can be code owners for docs files and review pull requests.
The main disadvantage of the sidecar pattern, in my opinion, is that it often treats documentation as an accessory, similar to tests or examples, if not less valuable. As with a real sidecar motorcycle, which is slower and has worst maneuverability, a repo hosting both docs and code can be less flexible and cause more conflicts, especially when docs and code have separate release cadences and governance, or when docs are blocking a release or risk jamming a pipeline due to badly formatted markup.
Orthogonal: docs and code never touch
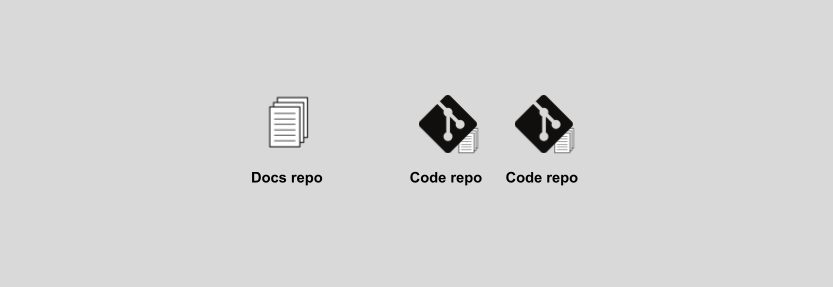
In the orthogonal pattern, official docs live in a single repository, while one or more public code repos continue hosting a mix of user and developer docs. Technical writers own the docs repo and developers maintain the docs in the code repos following the sidecar pattern. The docs repo contains code and settings for deploying and updating the docs site. The link between official docs and code is manual.
This model has few advantages and many drawbacks. Although it succeeds at giving the docs an identity of their own and much-needed autonomy, it fails at nurturing a healthy relationship with the developers. At the same time, it causes content duplication, as developers write docs in the code repos with no or little editorial support, content that writers reuse to write the official documentation. Users end up confused: should they browse the code repos for fresh docs or use the official site?
There are many ways of getting into an orthogonal setting. For example, when docs live in a CMS/CCMS, moving them to a single repository to convert them to docs-as-code is quite common. Or it may be that the product has both code and UI elements, writers taking care of the latter and trying to catch up with the rest. Whatever the reason, the orthogonal model risks creating siloes if writers don’t actively embed with developers.
I only see two solutions to an orthogonal pattern: Either you federate content or specialize the docs that reside in each type of repository.
Federated: docs as modular code
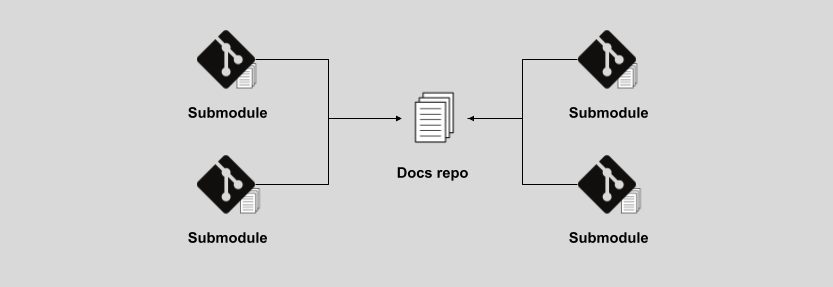
In the federated pattern, documentation is distributed across a network of code repositories, each covering a different feature or component. When docs are published, a central docs repository takes the content from each code repo and creates a single site following a unified structure and adding general documentation that applies to the whole product or to all components. Most of the docs are accessible from both the repositories and the official docs site. Writers and developers work together in each code repo.
Federating docs across code repositories makes sense when documenting strongly autonomous projects under the same umbrella. A good example of that is the OpenTelemetry docs repository, which, in addition to its own documentation, imports docs from code repositories within the organization using git submodules. CentOS uses Antora, a docs generator capable of building the docs from a variety of different repositories. By leveraging git’s abilities and modern CI/CD practices, content federation brings lots of flexibility and autonomy to teams.
Although federated content provides an interesting solution to orthogonal patterns by bringing all sidecar repos together, it might be hard to maintain. You need lots of discipline and a robust content strategy to orchestrate docs across multiple repositories. A network of submodules tied together by CI/CD pipelines might also turn out to be overly fragile; submodules in particular adds lots of complexity to git’s conceptual model, to the point that many developers actively avoid them.
Specialized: docs and code repos cooperate
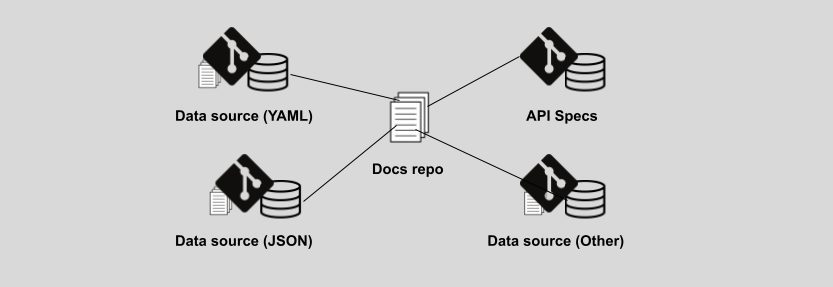
The phrase “Documentation should be tied to the implementation it describes” sounds good to my ears, except this can only happen when we’re talking of reference documentation and API documentation, and only when code comments and specification files are used correctly. When both conditions are met, you can build reference documentation by parsing JSON or YAML generated by the code, for example, or by using any other kind of intermediate representation.
A specialized pattern assumes that each kind of repo in an organization is capable of producing high-quality content that doesn’t overlap and can be integrated in a centralized location. For example, the main docs repository contains all the guides and conceptual information. In turn, specific content types, such as API reference or detailed list of settings, which are deeply connected to the code they originate from, are integrated by the docs site either at build or when the user loads the docs.
Like the federated pattern, this model tackles fragmentation by centralizing docs in a single repository, with an important difference: instead of letting each code repo do it all, it promotes division of labor, limiting the responsibility of producing reference and internal docs to code repos. The docs site becomes a product that behaves like a front-end experience, pulling data in from where it’s fresh. Code repos hold data and the docs site deals with the docs, some of which are a mix of manual and automatic content. It’s a win-win in that the code repos get to preserve their most important docs while letting the docs team pull that information on-demand.
The specialized pattern is also the closest to a classic editorial pattern, where only the docs repository contains the docs, though it aspires to be more pragmatic and able to adapt to the reality of complex products. It requires a strong automation culture in the docs team and a strong docs sensibility among developers, so that they can provide standardized, easy to parse data files. It’s entirely possible to transition from an orthogonal to a specialized pattern if writers are able to create a good relationship with developers and get their trust in all things documentation.
What’s the best one?
The best pattern is the one that helps you climb the Docs Hierarchy of Priorities in your current situation, which may or may not resemble the future. If you find yourself transitioning from one pattern to another, that’s probably because it’s the right time.
As Anne Gentle puts it in her classic Docs like Code:
To decide whether to keep docs in the dev repo, use a single docs repo, or use multiple docs repos, consider your users, contributors, reviewers, content size, deployed docs, and translated docs.